
Code Heroes: Nền tảng tra cứu và giải đáp pháp luật - Ứng dụng sáng tạo các mô hình ngôn ngữ lớn

Với khả năng tự động trích rút thuật ngữ, từ ngữ, và định nghĩa từ CSDL sẵn có, CodeHeroes cung cấp một cách tiếp cận thông minh cho việc tìm kiếm và hiểu rõ các điều khoản pháp luật. Nền tảng này không chỉ giúp người dùng tìm kiếm từ khóa và nội dung liên quan, mà còn sử dụng Deep Learning để đề xuất các thuật ngữ mới xuất hiện lần đầu trong văn bản QPPL. Qua việc cung cấp gợi ý, CodeHeroes tạo điều kiện cho người dùng cập nhật thông tin và góp phần nâng cao chất lượng CSDL thuật ngữ.
CodeHeroes không chỉ đơn thuần là công cụ tra cứu mà còn hỗ trợ trả lời câu hỏi pháp luật của người dùng thông qua việc trích rút tri thức từ các văn bản QPPL. Với tính năng gợi ý câu hỏi tương tự hoặc liên quan, cũng như đưa ra các đường link để hỏi giả có thể tìm hiểu sâu hơn về vấn đề, cùng diễn đàn cho phép giao lưu và chia sẻ kiến thức, CodeHeroes mang đến trải nghiệm học tập và nắm bắt pháp luật một cách tiện lợi và mạnh mẽ cho mọi người.
Sản phẩm là một dự án mã nguồn mở dành cho việc tra cứu và hiểu rõ hơn về các nội dung văn bản quy phạm pháp luật (QPPL) hiện đang có hiệu lực. Với mục tiêu chính là cung cấp một cách tiếp cận đơn giản và chính xác tới thông tin pháp luật, sản phẩm này sử dụng công nghệ để tự động trích rút, tra cứu và đề xuất các thuật ngữ mới một cách hiệu quả.
Sản phẩm không chỉ giúp người dùng tìm kiếm từ khóa và nội dung liên quan, mà còn áp dụng mô hình ngôn ngữ lớn để đề xuất các thuật ngữ mới trong văn bản QPPL. Điều này tạo điều kiện cho người dùng cập nhật thông tin và góp phần nâng cao chất lượng cơ sở dữ liệu. Sản phẩm cũng hỗ trợ người dùng đặt câu hỏi và nhận gợi ý từ các câu hỏi tương tự hoặc diễn đàn để thảo luận với các chuyên gia.
Với mục đích chính là cung cấp thông tin pháp luật chính xác và miễn phí cho mọi người, mã nguồn của sản phẩm này được công khai trên Github để cộng đồng phát triển có thể cùng đóng góp và cải thiện.
Việc ra đời sản phẩm nhằm mang đến cho người dùng một trải nghiệm mới trong việc tra cứu, tìm kiếm các nội dung văn bản QPPL, ngoài kế thừa những tính năng mà một pháp điển hiện tại có, thì sản phẩm còn phát triển và tạo ra những tính năng mới với mục tiêu đáp ứng những nhu cầu người dùng, từ đó tạo ra một hệ thống về pháp luật lâu dài và bền vững.
Các tính năng của sản phẩm
1. Tra cứu pháp điển
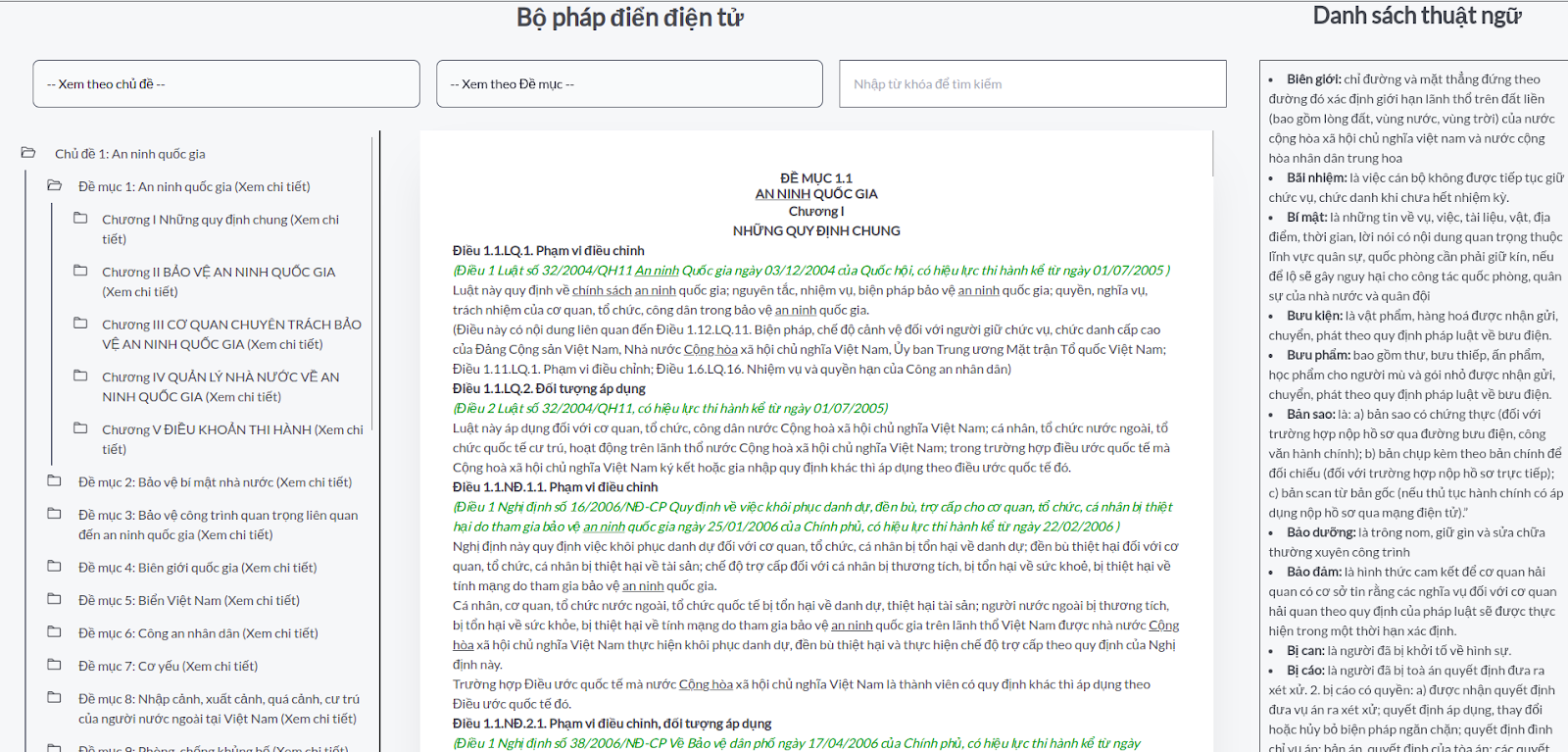
Tính năng này cho phép người dùng có thể tìm kiếm, xem những nội dung về QPPL dưới dạng cây (cây pháp điển), tính năng cung cấp cho người dùng một giao diện thân thiện, dễ sử dụng, người dùng có thể xem trực tiếp những thông tin pháp luật theo luật, theo điều khoản hoặc theo chỉ mục. Ngoài ra, để khắc phục trường hợp khi tra cứu một văn bản pháp luật người dùng có thể có những thuật ngữ không hiểu, hệ thống cung cấp cho người dùng một bảng gồm danh sách những thuật ngữ xuất hiện trong văn bản kèm theo và ngữ nghĩa của thuật ngữ đó, chính vì vậy, khi sử dụng hệ thống và tra cứu, người dùng sẽ không cần phải tìm kiếm những thuật ngữ ở ngoài mà có thể xem trực tiếp thuật ngữ tại trang tra cứu.
2. Tìm kiếm thuật ngữ từ văn bản:
Tính năng này cho phép người dùng tìm kiếm thuật ngữ từ 1 đoạn văn bản bằng cách dán nội dung vào ô lọc thuật ngữ, sau đó hệ thống sẽ tiến hành phân tích nội dung đoạn văn bản pháp luật từ đó đưa ra những thuật ngữ, bao gồm thuật ngữ đã có và đề xuất thuật ngữ với nếu thuật ngữ đó chưa có trong CSDL.
Việc đề xuất thuật ngữ mới được phân loại bằng cách sử dụng mô hình Deep Learning PhoBERT cho việc phân loại văn bản. Mô hình được đào tạo cho việc phân loại một câu có phải là một câu mang ý nghĩa là thuật ngữ hay không. Mô hình đã được đào tạo trên tập dữ liệu hơn 23000 câu bao gồm thuật ngữ trong các văn bản QPPL và các câu trong văn bản QPPL không phải là thuật ngữ. Cấu trúc của dữ liệu huấn luyện đảm bảo cấu trúc. [Danh từ] + [phần giải thích]. Có nghĩa là dữ liệu huấn luyện phải đúng cấu trúc trên và đó cũng là cấu trúc của một câu giải thích thuật ngữ trong các văn bản QPPL được công bố. Mô hình được công bố sử dụng miễn phí trên Hugging Face tại địa chỉ: https://huggingface.co/ShynBui/text_classification. Phần dữ liệu huấn luyện đã có sẵn trên GitHub hoặc có thể liên hệ với nhóm qua email: buitienphat240602@gmail.com.

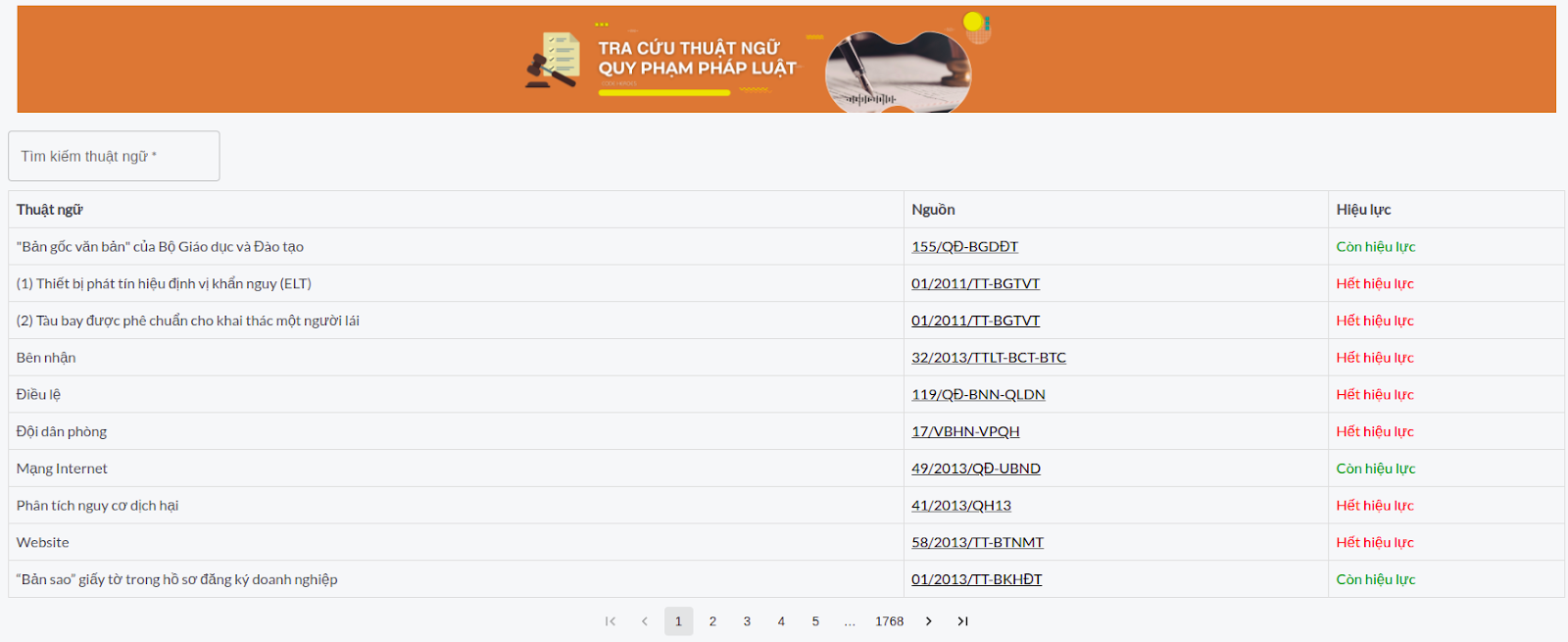
3. Tìm kiếm nhanh thuật ngữ
Ngoài việc xem thuật ngữ trực tiếp trong văn bản quy phạm pháp luật, thì người dùng cũng có thể tra cứu thuật ngữ dựa trực tiếp với tính năng tìm kiếm thuật ngữ này, hệ thống sẽ cung cấp cho người dùng danh sách tổng những thuật ngữ hiện có được sắp xếp theo thứ tự, người dùng có thể tìm kiếm theo từ khóa để tìm kiếm những thuật ngữ mà bản thân muốn xem, những thuật ngữ này bao gồm thuật ngữ, nội dung thuật ngữ, phạm vi của thuật ngữ (thuật ngữ thuộc văn bản QPPL nào), và thời gian hiệu lực (còn hiệu lực hay không).

4. Giải đáp pháp luật
Việc giải đáp pháp luật là chức năng quan trọng bậc nhất trong việc hỗ trợ người dùng trong việc tìm hiểu luật pháp. Dự án kết hợp nhiều phương pháp khác nhau để tạo thành quy trình truy vết - đọc hiểu, nhằm đưa ra câu trả lời cho câu hỏi của người dùng.
Chúng tôi có 2 cách tiếp cận như sau:
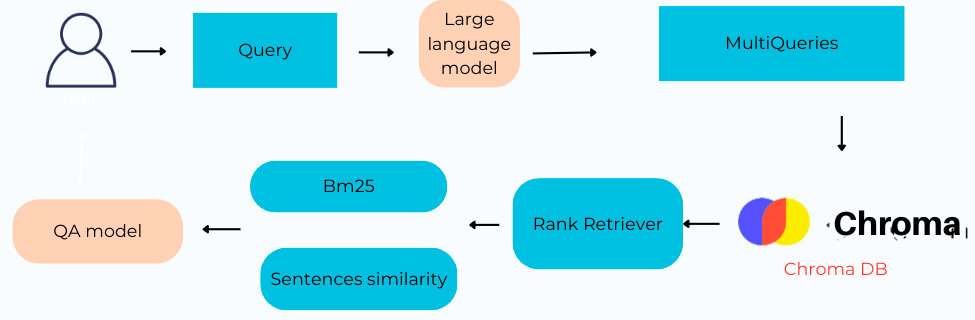
Ở phương pháp tiếp cận đầu tiên, khi người dùng đưa vào một câu hỏi, dựa vào GPT API chúng tôi tạo ra những câu hỏi liên quan tương tự. VD: Người dùng đưa vào câu: “Ông Phạm Nhật Vượng sinh năm nào ?”, hệ thống sẽ tạo ra những câu hỏi tương tự như “Năm sinh của ông Phạm Nhật Vượng ?”, “Sinh nhật của ông Phạm Nhật Vượng là ?”. Điều này cho phép hệ thống có miền tìm kiếm sâu rộng hơn cũng như giúp ta không bị bỏ sót các thông tin quan trọng là ngữ cảnh của câu hỏi đưa vào không được hệ thống nắm bắt rõ ràng. Tiếp theo, những câu hỏi được tạo ra cùng câu hỏi gốc được tìm kiếm trong một kho chứa vector, ở đây chúng tôi sử dụng ChromaDB - một sản phẩm mã nguồn mở trong lĩnh vực quản lý và truy vấn dữ liệu tương thích với nhiều hệ điều hành, để tiến hành tìm kiếm trên miền dữ liệu đã được vector hóa sẵn, dữ liệu ở đây chính là các văn bản QPPL đã được chúng tôi chuyển hóa thành các biểu diễn vector. Bằng cách sử dụng mô hình https://huggingface.co/sentence-transformers/all-MiniLM-L12-v2 trên Hugging Face và kĩ thuật BM25 chúng tôi đã tìm ra được các đoạn văn bản liên quan đến câu hỏi của người dùng. Cuối cùng, hệ thống sử dụng mô hình Question Answering cho tiếng Việt được nhóm tự phát triển dựa trên việc fine-tune mô hình PhoBERT cho nhiệm vụ hỏi đáp để đưa ra câu trả lời cho các văn bản đã được tìm ra ở trên và trả về đáp án cuối cùng. Mô hình Question Answering của nhóm được công khai trên Hugging Face: https://huggingface.co/ShynBui/vie_qa, dữ liệu đào tạo và tham số, cũng như kết quả đã được public trên GitHub và Hugging Face. Hoặc có thể liên hệ qua email: buitienphat240602@gmail.com.
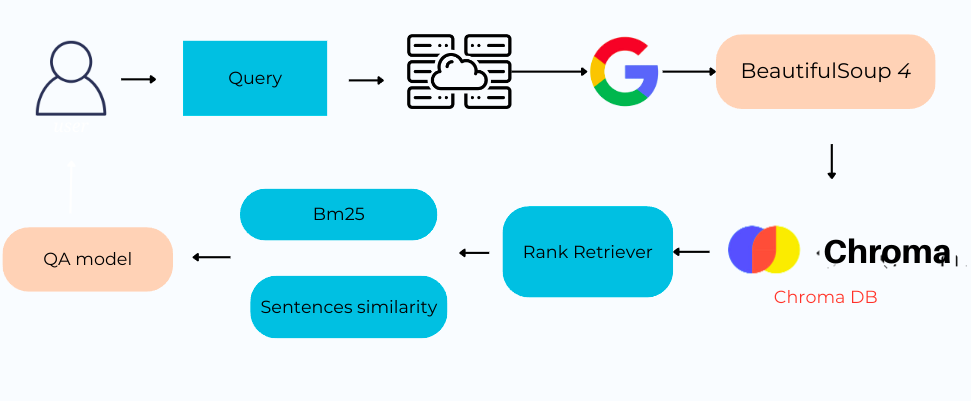
Ngoài cách tiếp cận trên, nhóm còn đề xuất một quy trình khác đó là thay vì sử dụng GPT API để tạo nhiều câu hỏi tương tự, ta có thể sử dụng thẳng sức mạnh của google search. Đầu tiên, ta nhận câu hỏi từ người dùng và tiến hành tìm kiếm trên Google. Ta sẽ nhận được những website có sự liên quan nhất - đây là cách chúng ta ứng dụng Custom Search của Google và tận dụng việc đánh chỉ mục sẵn của Google (cảm ơn Google vì tất cả). Khi đã có danh sách top các website liên quan nhất, ta sẽ rút trích toàn bộ thông tin trong website đó thông qua BeautifulSoup4 của Python. Bắt đầu từ bước này, chúng ta đã có thông tin động mà không cần phải cung cấp sẵn như cách tiếp cận trước, nó giúp ta có thể cập nhất thông tin mới nhất nhưng nhược điểm sẽ chậm hơn so với cách đầu tiên. Các bước tiếp theo như lưu trữ vào ChromaDB, retrieve đoạn văn bản, sử dụng đoạn văn bản đã truy vết vào mô hình Question Answering sẽ tương tự hướng tiếp cận đầu tiên.

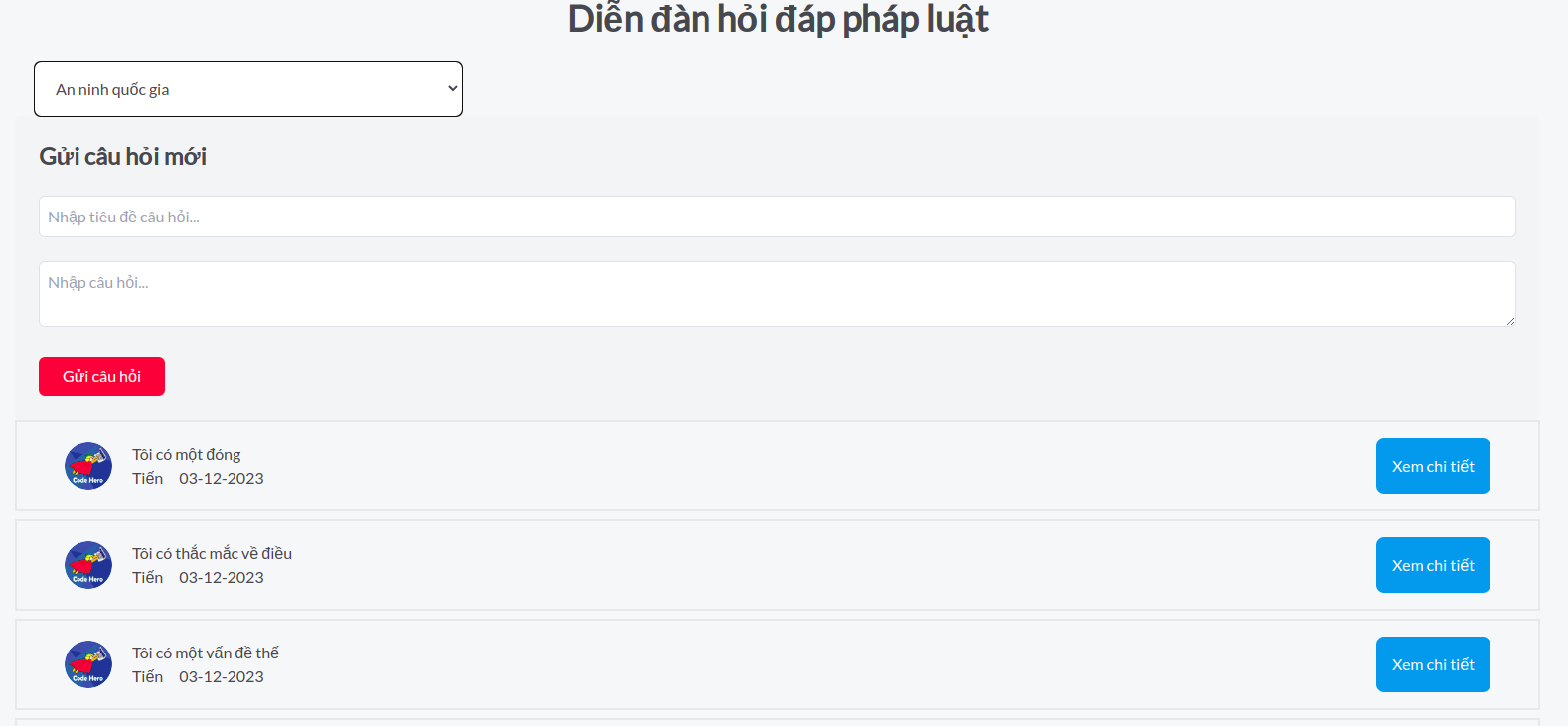
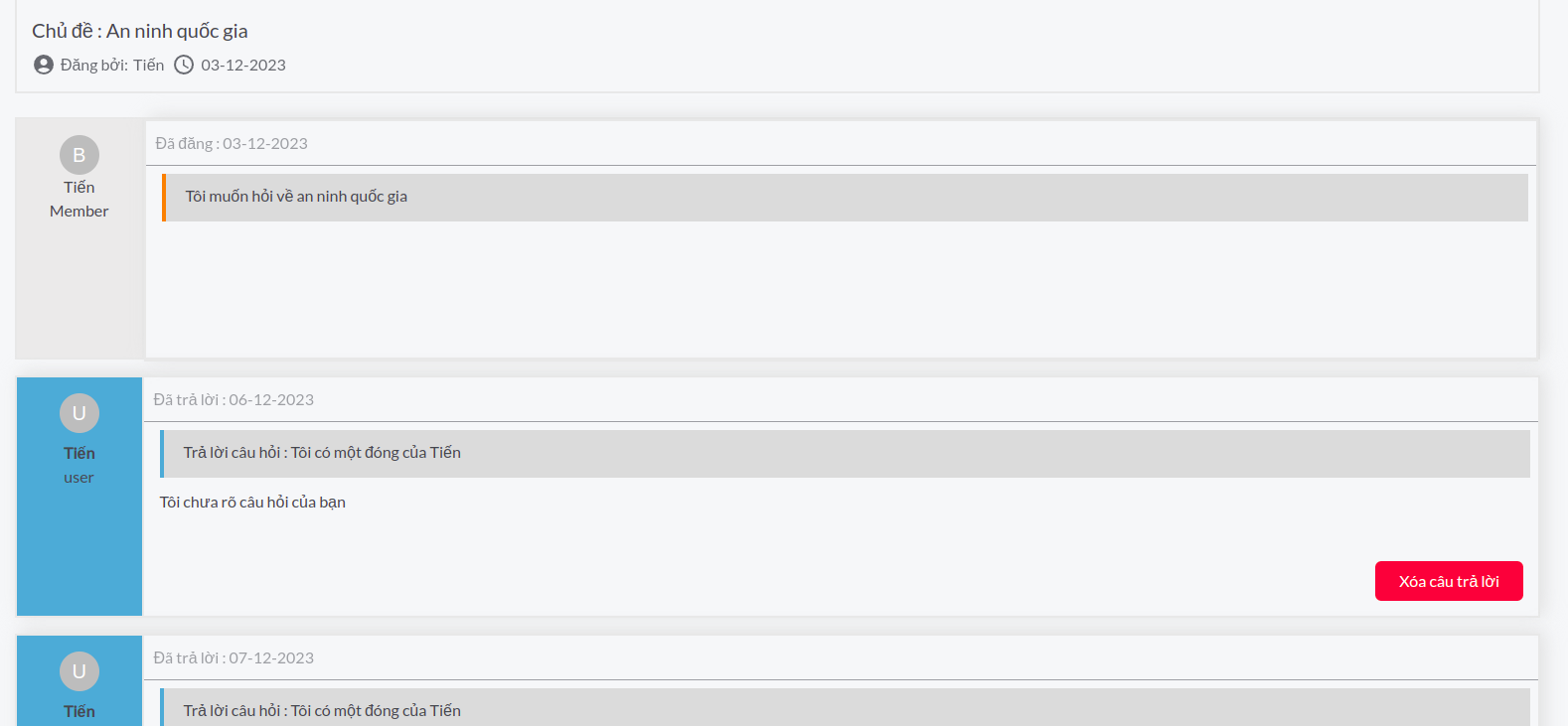
5. Hỏi đáp diễn đàn và đóng góp tri thức
Trong quá trình sử dụng hệ thống, ngoài những văn bản quy phạm pháp luật hiện hữu mà người dùng có thể tra cứu và tìm hiểu, thì chắc hẳn sẽ có những tình huống, câu hỏi cụ thể mà người dùng chưa biết phải xử lý thế nào dựa trên nền tảng pháp luật hiện có, và cũng sẽ có những chủ đề mà mọi người muốn chia sẻ với nhau nhiều hơn. Chính vì vậy, hệ thống cung cấp cho người dùng một diễn đàn, ở đây người dùng có thể hỏi đáp, chia sẻ những câu hỏi liên quan đến pháp luật hoặc tình huống pháp luật mà người dùng chưa hiểu, hoặc chia sẻ những chủ đề mới, với những câu hỏi thì những người dùng khác có thể tiến hành hỗ trợ những câu hỏi này, với các chủ đề mới thì những người dùng khác có thể tiến hành vào và thảo luận. các câu hỏi, chủ đề và trả lời được quản lý bởi admin hệ thống, nếu phát hiện những câu hỏi, chủ đề không phù hợp admin sẽ tiến hành loại bỏ.
Kiến trúc và công nghệ
Để phát triển và làm ra sản phẩm này, nhóm đã sử dụng các công nghệ phát triển web mạnh mẽ hiện nay như ReactJS, Python Flask, Docker. Cùng với đó là kết hợp với các nền tảng như Jenkins, Netlify, để thực hiện quá trình tự động quá CI/CD cho hệ thống.
-
ReactJS
ReactJS là một thư viện JavaScript phổ biến được phát triển bởi Facebook để xây dựng giao diện người dùng (UI) đơn trang và hiệu suất cao. Được ra mắt lần đầu tiên vào năm 2013, đây là một công nghệ mã nguồn mở giúp cho người dùng có thể dễ dàng tùy chỉnh và phát triển. Chính vì vậy nhóm đã quyết định sử dụng ReactJs để phát triển giao diện người dùng (front-end) cho hệ thống.
-
Python Flask
Flask là một microframework phát triển bằng Python để xây dựng ứng dụng web. Đây là một framework nhẹ và dễ sử dụng. Flask cung cấp các công cụ cơ bản cho việc xây dựng ứng dụng web và giữ cho mã nguồn ngắn gọn và đơn giản. Flask cung cấp những thư viện hỗ trợ cho việc lập trình web nhanh hơn như Flask-Security, Flask-SQL,... Tận dụng những ưu điểm này, nhóm chọn sử dụng Flask để phát triển phía server (back-end) cho hệ thống.
-
Docker
Docker là một nền tảng mã nguồn mở giúp đơn giản hóa việc triển khai và quản lý ứng dụng bằng cách đóng gói chúng cùng với tất cả các phụ thuộc của dự án vào trong các container. Containers cung cấp môi trường cô lập cho ứng dụng, giúp chúng có thể chạy mọi nơi mà không gặp vấn đề liên quan đến sự khác biệt trong môi trường hệ thống. Chúng ta có thể hiểu đơn giản Docker giúp cho việc triển khai một ứng dụng, bỏ qua các bước cài đặt, cấu hình phức tạp khi chạy một dự án. Nhóm sử dụng Docker để có thể đóng gói và triển khai trên môi trường internet và hỗ trợ thực hiện quá trình CI/CD.
Kiến trúc hệ thống
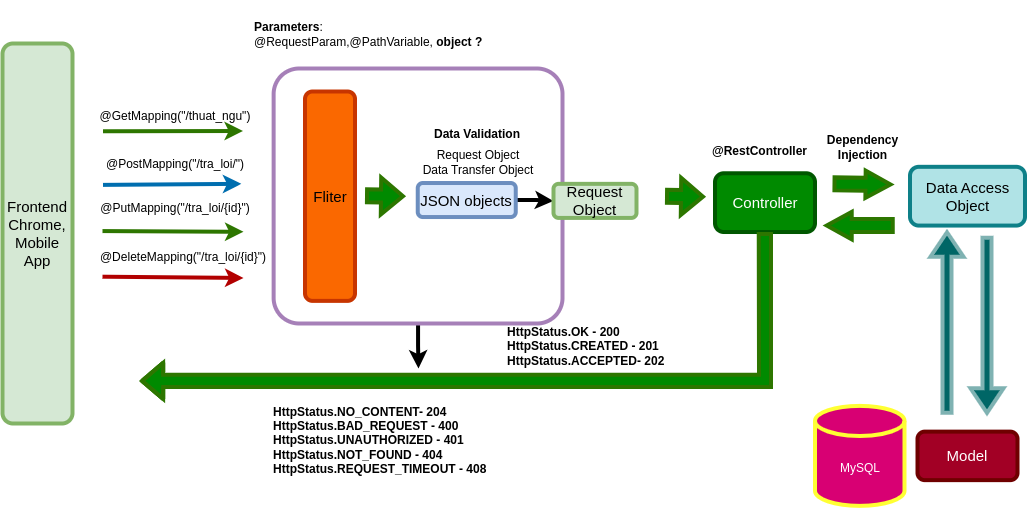
Đây là quy trình hoạt động cũng như kiến trúc của hệ thống, đầu tiên khi có một yêu cầu (request) gì từ phía browser, hệ thống sẽ tiếp nhận yêu cầu này, sau đó yêu cầu được đi qua một lớp filter, lớp này đóng vai trò để lọc ra những yêu cầu, xem có phù hợp hay không, nếu phù hợp thì đưa về các controller tương ứng để xử lý. Với mỗi Controller sẽ được kiểm tra, có những yêu cầu sẽ cần xác thực, hệ thống xác thực dựa vào JWT (JSON Web Token), token sẽ được phân giải và kiểm tra, nếu yêu cầu đủ quyền hạn thì sẽ cho thực hiện, ngược lại sẽ tiến hành trả về thông báo là UNAUTHORIZED (401) cho người dùng.
Trong quá trình thực hiện, nếu có yêu cầu nào cần thao tác tới cơ sở dữ liệu, lớp controller sẽ tiến hành gọi các phương thức trong DAO (Data Access Object) để thực hiện. Nhóm cũng áp dụng mô hình MVC (Model - View - Controller) trong quá trình phát triển ứng dụng, mỗi phần sẽ thực hiện một chức năng riêng và không liên quan đến nhau.
Kiến trúc CI/CD hệ thống
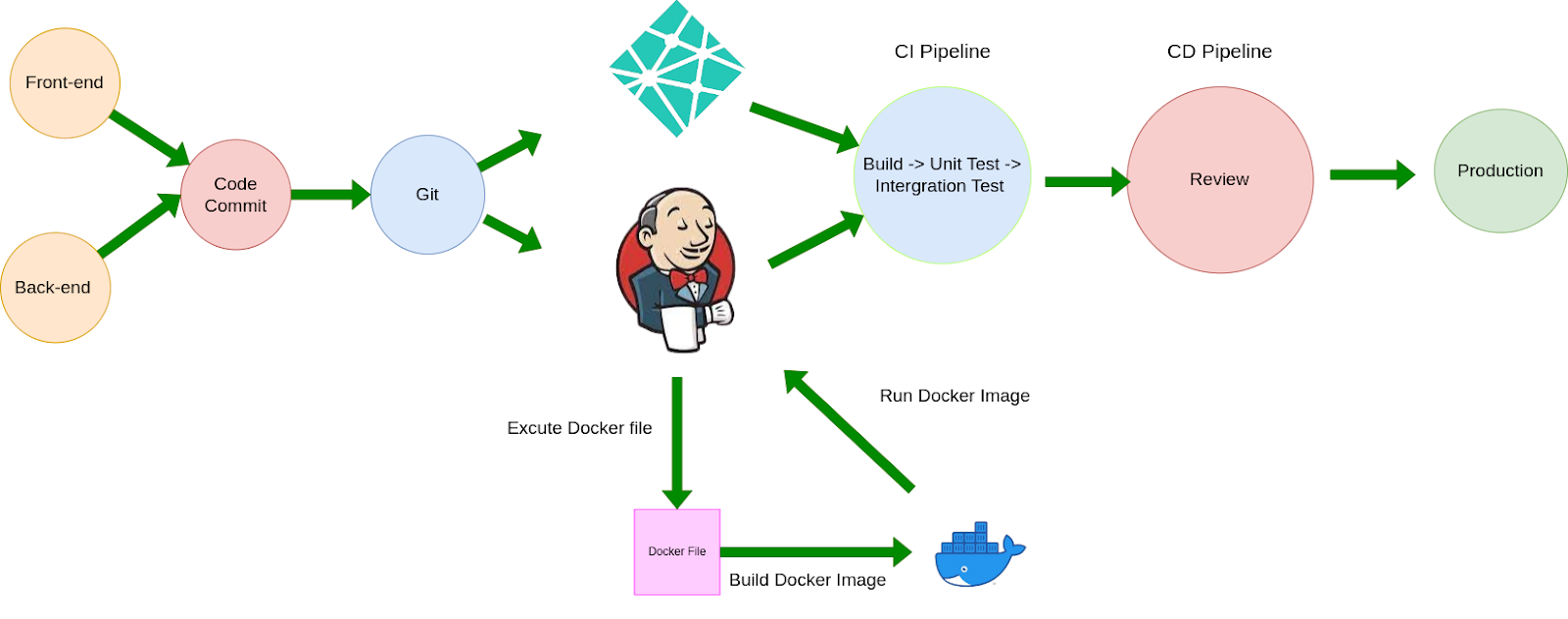
Đầu tiên áp dụng kiến trúc Microservices, nhóm tách riêng biệt 2 module front-end và back-end trên 2 server riêng.
Để thực hiện quá trình tự động hóa CI/CD cho hệ thống, nhóm sử dụng 2 công cụ là Netlify và Jenkins để triển khai, Netlify cho module front-end và Jenkins cho module back-end. Mỗi khi có một commit code mới từ 2 module này, 2 công cụ Netlify và Jenkins sẽ lấy mã nguồn mới từ git về và thực hiện 2 quá trình CI (Continuous Integration) và CD (Continuous Deployment), và cuối cùng khi các quá trình hoàn thành sẽ đưa ra một sản phẩm mới, quá trình được thực hiện tự động mà không cần tác động từ người phát triển.
Trong quá trình CI/CD với Jenkins thì có sử dụng thêm Docker để tạo ra môi trường xây dựng đồng nhất và cô lập, đảm bảo rằng mọi quy trình xây dựng và kiểm thử chạy trong môi trường tương đồng với môi trường sản xuất.
Sản phẩm được phát triển và duy trì bởi tập thể team CodeHeroes - đến từ trường Đại học Mở Tp. Hồ Chí Minh gồm 3 thành viên :
-
Bùi Tiến Phát : Phụ trách xây dựng và phát triển các mô hình LLM của hệ thống.
-
Nguyễn Đức Hoàng: Phụ trách xây dựng, phát triển server (back-end của hệ thống) và giao diện người dùng (front-end). Áp dụng các quy trình CI/CD cho hệ thống.
-
Tsàn Quý Thành: Phụ trách xây dựng, tìm kiếm và xử lý dữ liệu, phối hợp phát triển giao diện người dùng (front-end) của hệ thống. Tìm kiếm và báo cáo, phối hợp sửa các lỗi của hệ thống.
Giấy phép
Sản phẩm được phát triển và sử dụng theo giấy phép của : Apache License Version 2.0, January 2004
Sản phẩm mã nguồn mở về Pháp luật được trình bày thông qua trang web chính thức tại đây. Mã nguồn của sản phẩm được lưu trữ trên GitHub.
Tài liệu
Tài liệu hướng dẫn sử dụng sản phẩm có sẵn trong tệp README trên GitHub. Được viết trong định dạng Markdown (.md), nó tập trung vào công nghệ sử dụng, hướng dẫn cài đặt và triển khai mã nguồn trên máy cục bộ cũng như liên kết triển khai mã nguồn.
Để liên hệ hoặc đặt câu hỏi, bạn có thể gửi email đến buitienphat240602@gmail.com hoặc tìm kiếm thông tin trên GitHub.
Ngoài ra, sản phẩm cũng mở rộng mời giao lưu, thảo luận thông qua diễn đàn hoặc cộng đồng. Nếu bạn muốn tham gia phát triển sản phẩm, hãy liên hệ với chúng tôi.
Thông tin liên hệ chính thức có thể được tìm thấy trong phần "Author" trong tệp README.md trên GitHub.
Tác giả: Lan Nguyễn Thị Ngọc
Ý kiến bạn đọc
-
 VFOSSA ghi dấu ấn nổi bật tại FOSSASIA SUMMIT 2024
VFOSSA ghi dấu ấn nổi bật tại FOSSASIA SUMMIT 2024
-
 Thông báo chính thức về Hội nghị thượng đỉnh Nguồn Mở Châu Á - FOSSASIA Summit 2024 tại Hà Nội.
Thông báo chính thức về Hội nghị thượng đỉnh Nguồn Mở Châu Á - FOSSASIA Summit 2024 tại Hà Nội.
-
 Tổng kết sinh nhật VFOSSA lần thứ 12 (2012-2024)
Tổng kết sinh nhật VFOSSA lần thứ 12 (2012-2024)
-
 Thông báo lịch trình chương trình sinh nhật VFOSSA lần thứ 12
Thông báo lịch trình chương trình sinh nhật VFOSSA lần thứ 12
-
Thông báo chương trình sinh nhật VFOSSA lần thứ 12 (2012-2024)


- Đang truy cập70
- Máy chủ tìm kiếm3
- Khách viếng thăm67
- Hôm nay18,598
- Tháng hiện tại430,264
- Tổng lượt truy cập29,662,611